Load Packages¶
library(data.table) # the best data manipulation package
library(stringr) # process strings
library(magrittr) # pipe operator, e.g., "%>%"
library(lubridate) # for date and time processingInspect the Data¶
We select the price and trading data of all US common stocks from the CRSP database between 2023-01-01 and 2023-06-30. Each row represents a stock’s daily observation. There’re in total 4221 unique stocks with about 465k rows.
# read data
data = readRDS("data/crsp.rds")
# convert to data.table
setDT(data)
# print the first 3 rows
data[1:3]This is “panel data,” meaning it contains multiple stocks (cross-sectional) with each stock having multiple observations ordered by date (time-series).
Each combination of
permno(stock ID) anddatedetermines a unique observation, i.e., they’re the key.The dataset is first sorted by
permno, and thendateColumn definition:
permno: The unique ID provided by CRSP.date: Dateticker: Ticker. Note that the ticker of a stock can change, and hence it’s not recommended to usetickeras stock ID.industry: The industry classification determined using the first two digits of NAICS industry classification code. See the official document for more details.is_sp500:TRUEif the stock is in the S&P 500 list by mid-2023;FALSEif not.open: Daily openhigh: Daily highlow: Daily lowcap: Daily market capital (in $1000)dlyfacprc: Daily factor to adjust for price. (We won’t use it in the practice.)vol: Trading volume (number of shares traded)prcvol: Dollar trading volume, calculated as the number of shares traded multiplied by the price per share.retx: Daily return (excluding dividend).
Find out all stocks whose ticker contains "COM"¶
We use the str_detect function (from the stringr package) to find out all tickers that have "COM". But that’s only half the way. Without deduplicating (the unique() function), we will end up with numerous duplicate observations whose permno and ticker are the same but only differ in date.
We provide no arguments to unique(), meaning R needs to consider all columns.
data[str_detect(ticker, 'COM'), .(permno, ticker)
] %>% unique()Execution explained:
First, R executes
str_detect(ticker, 'COM')to filter out the needed rows.Then, it only keeps two columns,
.(permno, ticker). By then, we have many duplicates.Lastly, we use
unique()to remove the duplicates.
How many stocks on each day have positive/negative returns?¶
Since we want to count the stocks on each day, We need to first group all stocks by date and then by the return sign (positive vs. negative). Next, we need to generate two counts: one for the up (positive return) and the other for the down (negative). We leverage the sign of retx (return) to determine the direction of price change.
# step 1: create a new column "direction" which indicates the direction of the price change
data_q2 = data[, ':='(direction = sign(retx))]
data_q2 = data_q2[!is.na(direction)]
# step 2: count the stocks with +/- returns on each day
data_q2[, .(num=uniqueN(permno)), keyby=.(date, direction)][1:5]Output Explained:
On each day we have three observations (rows), one for each direction (1, 0, and -1) of the price change. For example, on 2023-01-03, there’re 1844 stocks with positive return.
Execution Explained:
In Step 1, we create a new column
directionto indicate whether we’re counting the up/down/no-move stocks for each day. Its value is 1, 0, or -1, depending on the sign ofretx.In Step 2, I group all observations by
date(since we want statistics for each day) and thendirection.uniqueN()is used to count the unique stock IDs within each group.
However, we don’t need to split the code explicitly. One great thing about data.table is that it can chain multiple computation steps together using [. In the following code, I put the creation of direction in the key argument.
# chain the two steps together (same results)
data[, .(num=uniqueN(permno)),
keyby=.(date, direction=sign(retx))
][!is.na(direction)][1:5]How many stocks on each day have positive/negative returns (only select stocks with market capital larger than $100M)?¶
Q3 is very similar to Q2, the only change is to use cap to filter stocks by market capital. Note that cap is in 1000 dollars.
# we only add the condition "cap>=1e5" to the first step
# the rest is the same
data[cap>=1e5,
.(num=uniqueN(permno)),
keyby=.(date, direction=sign(retx))
][!is.na(direction)
][1:5]How many stocks are there in each industry on each day?¶
data[, .(num=uniqueN(permno)),
keyby=.(date, industry)
][1:3]Execution Explained:
We first group by
dateandindustry, then we count the unique stock IDs within each gruop usinguniqueN()
Rank industries by their average daily number of stocks¶
This question is very similar to the previous one. But instead of counting stock numbers for each day, we will generate an average daily stock number through out the whole sample period and use that to rank the industries.
data[,
# step 1: count the number of stocks in each industry on each day
.(num_stk=uniqueN(permno)), keyby=.(industry, date)
# step 2: get the average number of stocks in each industry
][, .(num_stk=round(mean(num_stk))), keyby=.(industry)
# step 3: sort the industries descendingly by the average number of stocks
][order(-num_stk)
][1:3]Execution Explained
We first count the number of stocks for each industry on each day, as in the previous problem.
We then compute the average stock number across the sample period. Note this time we group by
industryinstead ofindustryanddate, this is because we want to average across the whole sample period.order(-num_stk)sort the results. the minus sign-indicates sorting desendingly. Without-(the default) the sort is ascending.
On each day, is the industry with the most stocks also generates the largest trading volume?¶
Some industries contain a lot of stocks, but it may not generate the largest trading volume (in dollars) because the component stocks may be very small. Let’s check if this claim is correct or not.
# for each industry, compute the total trading volume and stock number on each day
# we use `prcvol` as the trading volume
data_tmp = data[,
.(prcvol=sum(prcvol), num_stk=uniqueN(permno)),
keyby=.(date, industry)]
data_tmp[1:2]Output Explained:
prcvol: Total price trading volumenum_stk: number of stocks in this industry.
# for each day and each industry, we create two new columns:
# - `is_max_num_stk` indicates if this industry has the largest number of stocks
# - `is_max_prcvol` indicates if this industry has the largest trading volume
data_tmp = data_tmp[,
':='(is_max_num_stk = num_stk == max(num_stk),
is_max_prcvol = prcvol == max(prcvol)),
keyby=.(date)]
data_tmp[1:2]# for each day, we select the industry with the largest number of stocks,
# and `is_max_prcvol` will tell us if this industry has the largest trading volume
data_tmp[is_max_num_stk==T][1:3]Output Explained:
Each day only has one observation in the final output. It tells us what’s the industry with the largest number of stocks (
is_max_num_stk==T), andis_max_prcvoltells us if this industry generates the largest trading volume.As you can see, “Manufacturing” is the industry with the most stocks, and it generates the largest price trading volume.
Chaining everything together, we can rewrite the above code as:
data[,
# compute total trading volume and stock number
.(prcvol=sum(prcvol), num_stk=uniqueN(permno)),
keyby=.(date, industry)
][,
# add indicators
':='(is_max_num_stk = num_stk == max(num_stk),
is_max_prcvol = prcvol == max(prcvol)),
keyby=.(date)
][
# only keep the industry with the largest number of stocks
is_max_num_stk==T][1:3]How many stocks on each day have a gain of more than 5% and a loss more than 5%?¶
Similar to Q2, the key is to group the stocks by date and the direction of change.
data[
# filter stocks
retx>=0.05 | retx<=-0.05,
][,
# create `direction` to indicate price change direction
':='(direction=ifelse(retx>=0.05, 'up5%+', 'down5%-'))
][,
# count the stocks
.(num_stk=uniqueN(permno)),
keyby=.(date, direction)
][1:5]Execution Explained:
retx>=0.05 | retx<=-0.05: Only select observations with the required retx range. This will reduce the data size for the next step, and hence speed up the execution.':='(direction=ifelse(retx>=0.05, 'up5%+', 'down5%-')): We useifelseto indicate the direction: ifretx>=0.05is met, thendirectionis “up5%+”, otherwise, the value is “down5%-”.
What are the daily total trading volume of the top 10 stocks with the largest daily increase and the top 10 stocks with the largest daily decrease?¶
data[
# sort by date and retx
order(date, retx)
][,
# compute the total trading volumn of the top/bottom 10
.(bottom10 = sum(prcvol[1:10]), top10 = sum(prcvol[(.N-9):.N])),
keyby=.(date)
][1:5]Execution Explained:
We first sort (ascendingly) by
dateandretx, which facilitates selecting the top/bottom 10 stocks based onretx.bottom10 = sum(prcvol[1:10]): This line computes the total trading volume for the bottom 10 stocks.prcvol[1:10]: It selects the first 10 elements of theprcvolvector. Remember that previously we’ve sorted byretx, so these 10 observations also have the smallest (i.e., most negative)retxvalue.sum(): Computes the total trading volume for these 10 observations.
top10 = sum(prcvol[(.N-9):.N]): Similar to the above, except that we use a special symbol.N..Nis unique todata.table, and it equals the number of observations in each group. Since we have grouped the observations bydate(keyby=.(date)), then.Nequals the number of observations on each day.prcvol[(.N-9):.N]: It selects the last 10 elements of theprcvolvector. Since within each date, the data is sorted ascendingly byretx,prcvol[(.N-9):.N]is also the 10 observations with the largest (most positive)retx.
How many stocks increase by 5% at the time of open and close?¶
Sometimes, good news is released to the market over the night when the market is closed. In this case, price can only react to the news when the market opens in the next day. Instead, if the news is released during trading hours, then the market will react to it immediately. Let’s count how many stocks fall in these two categories.
data[,
# `pre_close` is the previous day's close price
':='(pre_close=shift(close, 1)),
keyby=.(permno)
][,
# create a new column `ret_open` representing the return at the time of open
':='(ret_open = open/pre_close -1)
][,
.(num_open=sum(ret_open>=0.05, na.rm=T),
num_close=sum(retx>=0.05, na.rm=T)),
keyby=.(date)
][1:5]Output Explained:
num_open: Number of stocks that increase by 5% at the time of open, i.e., (“open price” / “prev day’s close”) - 1 >= 0.05num_close: Number of stocks that increase by 5% at the time of close, i.e., (“close price” / “prev day’s close”) - 1 >= 0.05
Execution Explained:
':='(pre_close=shift(close, 1)): We use theshiftfunction (fromdata.table) to create a new column representing the previous day’s close price.1means the lag is only one period.':='(ret_open = open/pre_close -1):ret_openis the return at the time of open.num_open=sum(ret_open>=0.05, na.rm=T):num_openis the number of stocks that increase by 5% at the time of open. The result ofret_open>=0.05is a boolean vector (whose elements can only beTRUEorFALSE) with the same length asret_open.sum(ret_open>=0.05, na.rm=T)will add up all the elements in this boolean vector, whereTRUEis treated as 1 andFALSEis treated as 0. Basically, whatsum(ret_open>=0.05, na.rm=T)does is to count the number of elements inret_openthat are larger than 0.05.na.rm=Tis used to ignoreNA.
What’s the correlation coefficient between trading volume and return?¶
Does more people trading a stock necessarily push the stock price higher or lower? Let’s check this claim!
# Step 1: compute two versions of volume: vol and vol_change
data_q10 = data[order(permno, date)
][, .(vol, vol_change = vol - shift(vol), retx, cap),
keyby=.(permno)
] %>% na.omit()
# Step 2: compute corr
data_q10[,
# compute corr for individual stocks
.(corr1=cor(vol, retx), corr2=cor(vol_change, retx), weight=mean(cap)),
keyby=.(permno)
# compute the weighted average of corr
][, .(corr1=weighted.mean(corr1, weight, na.rm=T),
corr2=weighted.mean(corr2, weight, na.rm=T))]Output Explained:
Well, the correlation between trading volume and return is very low: from 0.005 to 0.03, depending on how the trading volume is defined.
Execution Explained:
In Step 1, we create two versions of trading volume:
vol, which is its raw value, andvol_change, which is the change in vol.We use
na.omit(fromdata.table) to remove any line that contains anNA.In Step 2, we first compute the corr for each individual stock, resulting in
corr1andcorr2. We also create a new columnweightwhich is the average market capital of each stock.weightwill be used when we compute the weighted average of corr coefficients.We use
weighted.meanto compute the weighted average of corr.
What’s the correlation between trading volume and the magnitude of return?¶
From Q10 we’ve learned that trading volume and return is rarely correlated. However, trading volume may still be correlated with the magnitude of return: the more people trade a stock, the larger the price movement (either direction) could be. Let’s verify this hypothesis!
We’ll use focus on individual-stock-level (instead of industry-level) this time.
Instead of using retx (return), we’ll use abs(retx) (the absolute value of retx) to represent its magnitude.
data[,
# compute the individual-level correlation, also compute the average market cap
.(corr=cor(vol, abs(retx)), weight=mean(cap)), keyby=.(permno)
# compute the weighted average of corr across stocks
][, weighted.mean(corr, weight, na.rm=T)]Output Explained:
Wow! Now the correlation is much strong: jump from less than 0.05 to 0.46!
What’s the correlation between industry-level trading volume and industry-level return?¶
Q11 is an extension of Q10. Instead of focusing on individual stocks, we aggregate stocks within the same industry. Will such aggregation improve the correlation?
Again, we use the first two digits of naics as a proxy of industry.
data[,
# Step 1: create industry-level volume, return and market cap
.(ind_vol=sum(vol, na.rm=T), ind_ret=weighted.mean(abs(retx), cap, na.rm=T),
ind_cap=sum(cap, na.rm=T)),
keyby=.(industry, date)
# Step 2: calculate the correlation for each industry
][, .(corr=cor(ind_vol, ind_ret), ind_cap=mean(ind_cap)), keyby=.(industry)
# Step 3: compute the weighted average of corr
][, .(corr=weighted.mean(corr, ind_cap, na.rm=T))]Output Explained:
Well, the correlation is weaker 😂.
Execution Explained:
In Step 1, we compute the industry-level trading volume, return, and market cap on each day
ind_vol: Industry volume is defined as the sum of all trading volumes within the industry.ind_ret: Industry returnind_retis defined as the value-weighted average of all stock returns within the industry. We use market capitalcapas the weight.ind_cap: The industry’s daily aggregated market capital. We’ll use it in the later stage.
In Step 2, we compute the correlation coefficient for each industry. Note that we also create a new
ind_capdefined asind_cap=mean(ind_cap). It’s the average market capital of the industry.In Step 3, we compute the weighted average of corr. We use
ind_capcalculated in Step 2 as the weight.
What’s the industry distribution of S&P 500 stocks?¶
This problem requires us to count the number of S&P 500 stocks in each industry.
data[
# select the S&P 500 stocks
is_sp500==T,
# count the number of stocks in each industry
.(num_stk=uniqueN(permno)),
# group by industry
keyby=.(industry)
][
# sort descendingly by the number of stocks
order(-num_stk)
][1:5]What’s the return volatility of each industry?¶
We first compute industry-level return on each day and then computes its volatility.
data[,
# Step 1: compute industry return on each day
.(ind_ret=weighted.mean(retx, cap, na.rm=T)),
keyby=.(industry, date)
][,
# Step 2: compute the standard deviation of industry return
.(volatility=sd(ind_ret)), keyby=.(industry)
# sort results
][order(-volatility)
][1:5]Execution Explained:
Step 1: We first group the data by
industryanddate, which allows us to compute the industry return on each day. The industry return is calculated as the weighted mean (weighted.mean) of the component stocks, where the weight is the stock’s market capital (cap).Step 2: We define return volatility as the standard deviation (
sd) of the return.
⭐️ What’s the correlation matrix of different industries?¶
# Step 1: calculate the industry-level return
ret_ind = data[, .(ret_mkt=weighted.mean(retx, cap, na.rm=T)), keyby=.(industry, date)]
# Step 2: pivot the industry return table
ret_ind2 = dcast(ret_ind, date~industry, value.var='ret_mkt')
ret_ind2[, ':='(date=NULL)] # remove the date column
# Step 3: compute the correlation matrix
cor(ret_ind2)
# -------------------
# The above three steps can be chained together as follows:
# data[, .(ret_mkt=weighted.mean(retx, cap, na.rm=T)), keyby=.(industry, date)
# ][, dcast(.SD, date~industry, value.var='ret_mkt')
# ][, ':='(date=NULL)
# ][, cor(.SD)]Output
Execution Explained:
Step 1: Nothing new here.
Step 2: We use
corto generate the correlation matrix. You may be wondering whatdcastis doing here. We usedcastbecause it “pivots” the table so it can satisfy the requirement of thecorfunction: each column must represent the returns of one industry.Let’s print out
ret_ind(beforedcast) andret_ind2(afterdcast) to get a sense of whatdcastis doing.
# (before `dcast`)
print(ret_ind) # column `ret_mkt` stores the returns for *all* industries
#> industry date ret_mkt
#> 1: Accommodation and Food Services 2023-01-03 0.002703254
#> 2: Accommodation and Food Services 2023-01-04 0.018852215
#> 3: Accommodation and Food Services 2023-01-05 -0.008638118
#> 4: Accommodation and Food Services 2023-01-06 0.023222487
#> 5: Accommodation and Food Services 2023-01-09 -0.001595260
# (after `dcast`)
print(ret_ind2) # now each column only stores the return of one industry
#> Transportation and Warehousing Utilities Wholesale Trade
#> 1: 0.001654837 -0.004928265 -0.003529841
#> 2: 0.017020174 0.010504283 0.006552128
#> 3: -0.013090004 -0.019094989 -0.011908121
#> 4: 0.034663817 0.020957761 0.026902487
#> 5: 0.010606304 0.006563325 -0.002127530As you can see, dcast reshapes the table from a “long” to a “wide” format.
⭐️ What’s the largest/smallest stocks in S&P 500 on each day?¶
Here we measure the size of a stock by its market capital. This problem involves some advanced techniques of data.table.
data[
# Step 1: select the S&P 500 stocks
is_sp500==T, .(date, ticker, cap)
# Step 2: sort by date and market cap
][order(date, cap)
# Step 3: select the smallest and largest stocks on each day
][, c(type=list(c('smallest', 'largest')),
.SD[c(1,.N)]),
keyby=.(date)
][1:6]Output Explained:
Each day (e.g., 2023-01-03) has two rows, one for the smallest stock and the other for the largest. The
typecolumn indicate the type.
Execution Explained:
Step 1: We select S&P 500 stocks.
.(date, ticker, cap)allows us to only include the variable of interests.Step 2: We sort by
dateandcap. This is important. Because by doing that, in Step 3 where we group bydate, the first observation in each group will be the smallest stock (measured bycap), and the last observation will be the largest stock.Step 3: We first group by
date..SD[c(1,.N)]will extract the first (1) and the last (.N) row in each group (.Nrepresents the number of rows in the current group)..SD(meaning Subset of a Data table) is a special symbol provided bydata.table, and it represents all the data for the current group. Because in Step 2 we already sort bydateandcap,.SD[c(1,.N)]corresponds to the smallest and largest stock.I use
type=list(c('smallest', 'largest'))to add a new column to indicate which row represents the smallest and which row represents the largest. I also usec()to concatenate the newly createdtypecolumn and the columns returned by.SD.You can remove
type=list(c('smallest', 'largest')), and the result will be the same, just a bit less reading friendly. See below (see how thetypecolumn disappears):
data[
# Step 1: select the S&P 500 stocks
is_sp500==T, .(date, ticker, cap)
# Step 2: sort by date and market cap
][order(date, cap)
# Step 3: select the smallest and largest stocks on each day
][, .SD[c(1,.N)],
keyby=.(date)
][1:6]What is the ratio of the maximum trading volume to the minimum trading volume in each industry on each day?¶
This problem asks us to:
On each day and within each industry, find out the maximum and minimum trading volume.
Compute the ratio.
data[
# Step 1: sort by date, industry and dollar trading volume
order(date, industry, prcvol)
# Step 2: compute ratio for each industry on each day
][, .(ratio = prcvol[.N]/prcvol[1]),
keyby=.(date, industry)
][1:5]Execution Explained:
In Step 1: we sort by date, industry and dollar trading volume. This is important because if we group by
dateandindustrylater, the first (last) row in each group will have the smallest (largest) trading volume. This technique is also used in the previous problem, and will be used through this book.In Step 2: we first group by
dateandindustry, and then compute ratio withratio = prcvol[.N]/prcvol[1]. As explained earlier,prcvol[.N](the last row) andprcvol[1](the first row) correspond to the largest and smallest trading volume.
What’s the sum of the dollar trading volume for the top 5 stocks in each industry on each day?¶
We first find out the top 5 stocks with the largest dollar volume in each industry on each day, then we add them up.
data[
# Step 1: sort by date, industry and dollar trading volume
order(date, industry, -prcvol)
][,
# Step 2: get the total trading volume of the top 5 stocks
.(prcvol=sum(prcvol[1:5])), keyby=.(date, industry)
][1:3]Execution Explained:
Step 1: We first sort by
date,industryand-prcvol(-prcvolmeans sort byprcvoldescendingly). By doing that, when we group bydateandindustryin Step 2,prcvol[1:5]will correspond to the largest 5 values ofprcvol.Don’t leave out the minus sign in
-prcvol. Otherwise,prcvolwill be sort ascendingly and henceprcvol[1:5]will correspond to the smallest 5 values ofprcvol.
Step 2: Calculate the total trading volume.
⭐️ In each industry, what’s the daily average return of stocks whose dollar trading volume exceeds the 80th percentile of the industry?¶
data[,
# Step 1: only keep rows whose trading volume is in the top 20%
.SD[prcvol>=quantile(prcvol, 0.8)],
keyby=.(date, industry)
# compute the average return
][, .(avg_ret=weighted.mean(retx, cap, na.rm=T)),
keyby=.(date, industry)
][1:3]Execution Explained:
In Step 1, we first group by
dateandindustry. Next, within each group, we only want to keep rows whose dollar trading volume is larger than the 80th percentile, i.e., lines that satisfyprcvol>=quantile(prcvol, 0.8). The results ofprcvol>=quantile(prcvol, 0.8)is a boolean vector with the same length asprcvol, whereTRUEmeans the condition is met whileFALSEmeans not. We use this boolean vector to select the data:.SD[prcvol>=quantile(prcvol, 0.8)]. Remember that.SD(Subset of Data.table) is a special symbol indata.table, and it represents the current group. Basically, what.SD[prcvol>=quantile(prcvol, 0.8)]does is to only keep rows in.SDthat satisfy the condition.In Step 1, we compute the market-capital-weighted average return.
Extension:
If you just want to compute the average return instead of the value-weighted return, the following code is a simpler implementation (note how we use the results of prcvol>=quantile(prcvol, 0.8)] to select retx):
data[,
.(avg_ret = mean(retx[prcvol>=quantile(prcvol, 0.8)])),
keyby=.(date, industry)
][1:3]What’s the correlation coefficient between the average return of the top 10% stocks with the largest dollar trading volume and the bottom 10% stocks with the smallest dollar trading volume?¶
data_tmp = data[,
# Step 1: select the returns of the top/bottom 10% stocks by trading volume
.(ret_top10=retx[prcvol>=quantile(prcvol, 0.9)],
cap_top10=cap[prcvol>=quantile(prcvol, 0.9)],
ret_bottom10=retx[prcvol<=quantile(prcvol, 0.1)],
cap_bottom10=cap[prcvol<=quantile(prcvol, 0.1)]),
keyby=.(date)
][,
# Step 2: compute the weighted average return on each day
.(ret_top10=weighted.mean(ret_top10, cap_top10, na.rm=T),
ret_bottom10=weighted.mean(ret_bottom10, cap_bottom10, na.rm=T)),
keyby=.(date)]
data_tmp[1:3] # output of Step 2data_tmp[,
# Step 3: compute the correlation coefficient
cor(ret_top10, ret_bottom10)]Execution Explain:
Step 1: We select the top/bottom 10% stocks by trading volume. Note that we use the same technique used in the previous problem: Frist create a boolean vector with
prcvol>=quantile(prcvol, 0.9)and then use it to select the returns withretx[prcvol>=quantile(prcvol, 0.9)]. We also select the market capitalcapfor the top/bottom 10% stocks because we’ll use them as the weight in Step 2.Step 2: Compute the value-weighted return for each day.
Step 3: Compute the correlation coefficient.
⭐️ Find out the industries whose component stocks have a larger average dollar trading volume than the market average¶
To make sure we’re on the same page, my understanding of this problem is that it requires us to:
Calculate the average trading volume of stocks on the market on each day (i.e., we aggregate the trading volume of all stocks on the market and then divide by the number of stocks). This is the “market average.”
Similarly, calculate the average trading volume for stocks within each industry. So every industry will have its own value. This is the “industry average.”
Select all industries whose “industry average” is larger than the “market average.”
data[,
# Step 1: compute the "market average"
.(prcvol_mkt=weighted.mean(prcvol, cap, na.rm=T), industry, prcvol, cap),
keyby=.(date)
# Step 2: compute the "industry average"
][, .(prcvol_ind=weighted.mean(prcvol, cap, na.rm=T), prcvol_mkt=prcvol_mkt[1]),
keyby=.(date, industry)
# Step 3: only select industries whose average trading volume is larger than the market average
][prcvol_ind>prcvol_mkt
][1:5]Output Explained:
Take “2023-01-03” for example. This date has three rows (1-3), each representing an industry that meets our condition.
prcvol_indis the industry average dollar volume andprcvol_mktis the market average dollar volume.
Execution Explained:
Step 1: We first group by
date, because we want to include all stocks on each day to compute the market average..(prcvol_mkt=weighted.mean(prcvol, cap, na.rm=T), industry, prcvol, cap)does two things:It includes
industry,prcvolandcapin the output. These three columns are present in the original data. We include them because we’ll need them in Step 2.It also creates a new column
prcvol_mkt, which is the weighted average dollar trading volume of the market.
Step 2: We next group by
dateandindustry, because we want to calculate the industry average. The tricky thing isprcvol_mkt=prcvol_mkt[1], why do we need to explicitly select the first element ([1])? Let’s look at the full line of code:.(prcvol_ind=weighted.mean(prcvol, cap, na.rm=T), prcvol_mkt=prcvol_mkt[1]). This line creates two columns:prcvol_indandprcvol_mkt. Forprcvol_ind, the result is a scalar (a single number). However,prcvol_mktis a constant vector, meaning its elements are identical. This is understandable, for each industry, the “market average” should be the same. The problem is, if you put a scalar and a constant together in the output, the result will be “broadcasted,” meaning the scalar will be repeated until it has the same length as the vector. This is not desirable, and that’s why we also need to reduceprcvol_mktto a scalar byprcvol_mkt=prcvol_mkt[1].
If we don’t reduce prcvol_mkt to a scaler, the code and output will become like this (note that many duplicates are introduced):
data[,
# Step 1: compute the "market average"
.(prcvol_mkt=weighted.mean(prcvol, cap, na.rm=T), industry, prcvol, cap),
keyby=.(date)
# Step 2: compute the "industry average"
][, .(prcvol_ind=weighted.mean(prcvol, cap, na.rm=T), prcvol_mkt=prcvol_mkt),
keyby=.(date, industry)
][1:5]⭐️ What’s the daily “abnormal return” of each stock?¶
In finance, the daily stock return is conceptually viewed as the sum of two parts: a “baseline return,” which is the part that can be explained by some known factors (e.g., firm characteristics), and an “abnormal return” that cannot. As you can see, abnormal return is defined against how the baseline return is computed. In this example, we use the “market model” to calculate the baseline return, and the abnormal return is calculated as the raw stock return less the baseline return:
Assume is the raw daily return for stock on day ; is the market return on day . We first run the following regression:
The part is called the baseline return, because it’s something that can be explained by the coefficients of the regression. Abnormal return is hence defined as:
which is exactly the of the regression.
data[,
# Step 1: construct the market return
':='(ret_mkt=weighted.mean(retx, cap, na.rm=T)),
keyby=.(date)
][,
# Step 2: only keep stocks with at least 50 observations
.SD[.N>=50], keyby=.(permno)
][
# (optional) remove missing values
!is.na(retx)
][,
# Step 3: get alpha, beta, and AR
{
lm_out = lm(retx ~ ret_mkt)
alpha = coef(lm_out)[1]
beta = coef(lm_out)[2]
ar = resid(lm_out)
list(date, ar, alpha, beta)
},
keyby=.(permno)
][1:3]Execution Explained:
Step 1: We construct a new column
ret_mktto capture the daily value-weighted return of the whole market.Step 2: We remove any stock that has fewer than 50 observations (days) in the sample. (If there are too few observations, the regression results in Step 3 will not be robust.)
We first group by
permno, because the operation is for individual stocks.You should be familiar with
.SDnow, which represents the current group, i.e., the whole data for the currentpermno..N>=50:.Nis the number of rows in the current group; we require it to be no less than 50.
Step 3: The whole operations are wrapped in curly brackets, because we want to reuse what we’ve created in the
jpart (we also used this technique in this problem).We first group by
permno, because the regression is for individual stocks.We then regress the daily return on the market return,
lm(retx ~ ret_mkt), and save the result tolm_out.We use
coef(lm_out)to extract the coefficients of the regression results. The output is a list, with the first element being the intercept and the second element being the beta.We also use
resid(lm_out)to extract the residuals. That’s exactly the abnormal return we’re looking for.Finally, we specify what variables we want to put in the final output:
list(date, ar, alpha, beta)
⭐️ What’s the daily “self-excluding” industry return?¶
Let me explain the requirements of the problem. Suppose on day t, there’re three industries: A, B, and C, and their daily returns are “ret_A,” “ret_B” and “ret_A.” The problem asks us to calculate three versions of daily industry return: 1) the average of ret_A and ret_B, 2) the average of ret_B and ret_C, and 3) the average of ret_A and ret_C.
Specifically, for industry on day , its daily self-excluding return is defined as:
where
: total number of industries
: total number of stocks in industry .
: daily market capital of industry .
: daily return of industry .
We’re going to approach this problem as follows:
First, compute the daily average return for each industry.
We define industry average return as the value-weighed return of its component stocks. We’ve done this in this problem.
Second, calculate the self-excluding return.
# First, compute the daily average return for each industry
# For the definition of `ind_ret` and `ind_cap`, see the above explanation
ind_rets = data[,
.(ind_ret=weighted.mean(retx, cap, na.rm=T),
ind_cap=sum(cap, na.rm=T)),
keyby=.(date, industry)]
ind_rets[1:3]# Then, calculate the self-excluding return
ind_rets[,
{
# Step 1: create an empty vector to store the results
self_ex_ret = vector()
# Step 2: for each industry, compute the self-excluding return
for (i in 1:.N) {
self_ex_ret[i] = weighted.mean(ind_ret[-i], ind_cap[-i], na.rm=T)
}
# Step 3: return the results
list(industry, self_ex_ret)
},
keyby=.(date)
][1:3]Execution Explained:
Note that we wrap the whole j part in curly brackets again.
Step 1: We initialize the self-excluding return
self_ex_retas an empty vector (this helps to speed up the loop execution in Step 2).Step 2: We loop over each industry (from
1to.N). Note that we’ve already grouped bydate, so.Nis exactly the number of industries in each group.ind_ret[-i]represents the return vectorind_retwith the i-th element removed.ind_cap[-i]represents the market capital vectorind_capwith the i-th element removed.
⭐️ How many industries exceed the market average return on each day?¶
data[,
# Step 1: compute the market return
':='(ret_mkt=weighted.mean(retx, cap, na.rm=T)),
keyby=.(date)
][,
# Step 2: compute the industry return
.(ind_ret=weighted.mean(retx, cap, na.rm=T), ret_mkt=ret_mkt[1]),
keyby=.(date, industry)
][
# Step 3: calculate the number of stocks exceeding the market average
ind_ret>ret_mkt,
.(num_stk=.N, industry=list(industry)),
keyby=.(date)
][1:2]Execution Explained:
Step 1 and Step 2: Calculate the industry- and market-level return. We’ve done this many times in previous problems.
Step 3: Calculate the number of stocks exceeding the market average
ind_ret>ret_mkt(theipart) only selects industries that exceed the market average.num_ind=.Ncounts the number of industry.industry=list(industry). This part is interesting. It basically “packs” the multiple elements in a vector into a single element of a list, avoiding duplicated lines in the output. To understand that, recall thatindustryis a vector that contains all the industries that meet our criteria in the given day. Todata.table, each element ofindustrywill be expanded to a separate row. However, we only want to keep one row for each day in the output. By wrappingindustryusinglist, we collect all the industries into a single cell.
⭐️ How many stocks have experienced at least one daily price increase of 5%+ in the past three days? (Count the number on each day.)¶
To be clear, we define what’s “past three days” as follows: on day t, the previous three days are [t-3, t-2, t-1]. Of course you can have different definition as mine, but the solution is the same.
The challenge in Q9 is that we need to do rolling count. On day t, we need to query the values from (t-3):(t-1).
data[
# Step 1: convert the permno into a list
retx>=0.05, .(permno_list=list(permno)), keyby=.(date)
][, {
# Step 2: compute the number of stocks that open up 5% or more
num_stk_3d = vector()
for (i in 4:.N) {
num_stk_3d[i] = permno_list[(i-3):(i-1)] %>%
unlist() %>% unique() %>% length()
}
list(date, num_stk_3d)
}
][!is.na(num_stk_3d)
][1:3]Execution Explained:
Step 1: We first select stocks with daily return larger than 5% (
retx>=0.05), then we create a new columnpermno_listwhich represents allpermnoin a given day as alist(see the output below).Converting to a list is important because it allows us to collect all the stocks across different days and run deduplication in Step 2.
Step 2: We compute the number of stocks that open up 5% or more in the previous three days.
num_stk_3d = vector(): We first create an empty vector, it will store all thepermnos (stock IDs) that open up 5% or more.for (i in 4:.N)...: This is the key part of the code. Let’s takeito be 4 and see what it does.permno_list[(i-3):(i-1)]becomespermno_list[1:3], that is, the stock IDs in the first three days. Note thatpermno_list[1:3]is a list of three elements, where each element represents a day.%>% unlist(): Theunlistfunction “unpacks (flatterns)”permno_list[1:3]so the result becomes a non-nested list of stock IDs.%>% unique(): Remove any duplicated stock IDs.%>% length(): Count the number of stocks.As you can see, when
iequals 4, we count from day 1 to 3. Similarly wheniequals 5, we count from day 2 to 4.
list(date, num_stk_3d): Collect the final output columns and pack them into a list. This is required bydata.tableif thejpart is wrapped by curly brackets{...}(if you don’t know what’s thejpart please see the introduction ofdata.table). You can think of this line as areturncommand but with thereturnkeyword hidden.
⭐️ How many stocks outperform the market average return on all of the past three days?¶
This problem is very much like the one we’ve just solved. The difference is that in the previous problem, stocks that meet the criteria in any of the past three days will be included, but this time we require that the stocks have to meet the criteria on all* of the past three days.
Try to do it yourself before continuing.
data[
# Step 1: Compute the market average return
, ':='(ret_mkt=weighted.mean(retx, cap, na.rm=T)), keyby=.(date)
][
# Step 2: Convert the stocks meeting the criteria into a list
retx>=ret_mkt, .(permno_list=list(permno)), keyby=.(date)
][, {
# Step 3: compute the number of stocks that meet the criteria
num_stk_3d = vector()
for (i in 4:.N) {
num_stk_3d[i] = Reduce(
intersect,
permno_list[(i-3):(i-1)]
) %>% length()
}
list(date, num_stk_3d)
}
][!is.na(num_stk_3d)
][1:3]
⭐️ How many stocks outperform the market at least for two out of the past three days?¶
Now let’s make the problem harder!
data[
# Step 1: Compute the market average return
, ':='(ret_mkt=weighted.mean(retx, cap, na.rm=T)), keyby=.(date)
][
# Step 2: Convert the stocks meeting the criteria into a list
retx>=ret_mkt, .(permno_list=list(permno)), keyby=.(date)
][, {
# Step 3: compute the number of stocks that meet the criteria
num_stk_3d = vector()
for (i in 4:.N) {
num_stk_3d[i] = permno_list[(i-3):(i-1)] %>% unlist() %>%
table() %>% .[.>=2] %>%
length()
}
list(date, num_stk_3d)
}
][!is.na(num_stk_3d)
][1:3]
As you can see, the key change is in Step 3, where we use
permno_list[(i-3):(i-1)] %>% unlist() %>%
table() %>% .[.>=2]The above lines of code find out stocks that at least appear two times in the previous three days. To better understand how it works, let’s look at a simpler example:
# suppose we have a list with three elements, each elements is a vector containing letters
l = list(c('a', 'b', 'c'), c('a', 'b', 'f'), c('a', 'h', 'i'))
# Now we want to find out the letters that appear at least two times in the list
l %>% unlist() %>% table() %>% .[.>=2] %>% names()
#> [1] "a" "b"
# To understand the above line, let's break it down:
l %>% unlist() # unpack
#> [1] "a" "b" "c" "a" "b" "f" "a" "h" "i"
l %>% unlist() %>% table() # count frequency of each letter
#> .
#> a b c f h i
#> 3 2 1 1 1 1
l %>% unlist() %>% table() %>% .[.>=2] # only keep frequencies >= 2
#> .
#> a b
#> 3 2
l %>% unlist() %>% table() %>% .[.>=2] %>% names()
#> [1] "a" "b"If you understand the above example, you won’t have any problem in understanding the answer key.
In each month, how many stocks outperform the market?¶
Let’s make sure our understanding of this problem is on the same page: This problem requires us to compare the monthly return of the stocks and the market, not daily.
In the following solution, I put the calculation of monthly “stock” and “market” returns in two separate cells. It’s because the computation requires us to aggregate the data on different levels: to compute market return, we only aggregate on year-month, but for stock return, we need to aggregate on year-month as well as on the individual stock level. So it’s better to process them separately.
#--- Calculate the monthly "market" return ---#
mon_ret_mkt = data[
# Step 0: sort by permno and date
order(permno, date), .(permno, date, retx, cap)
][,
# Step 1: create the daily market return
.(ret_mkt=weighted.mean(retx, cap, na.rm=T),
yearmon=floor_date(date, 'month')),
keyby=.(date)
][,
# Step 2: create the monthly market return
.(mon_ret_mkt=prod(1+ret_mkt)-1),
keyby=.(yearmon)
]
mon_ret_mkt[1:3]Execution Explained:
Most of the above code shouldn’t be unfamiliar to you by now. There’re two places worth noting:
In Step 1, we create a month indicator by using the
floor_datefunction from thelubridatepackage.floor_date(date, 'month')will floor every date to the beginning of the month (note here we specify the rounding unit to “month”), e.g., “2023-05-23” will be floored to “2023-05-01.” This quickly creates a month indicator.In Step 2, we use
prod(1+ret_mkt)-1to compute the monthly market return.prodis essentially , which multiply all elements in the given vector. Becauseret_mktis the daily market return, the result ofprod(1+ret_mkt)is the net value at the end of the month. We take1from the result, yielding the market return over the past month.
#--- Calculate the monthly "stock" return and count the required stocks ---#
data[
# Step 0: sort by permno and date
order(permno, date), .(permno, date, retx, cap)
][,
# Step 1: create a month indicator
':='(yearmon=floor_date(date, 'month'))
][,
# Step 2: calculate the monthly return for stocks
.(mon_ret_stk=prod(1+retx)-1),
keyby=.(yearmon, permno)
][
# Step 3: merge the market return to the stock return
mon_ret_mkt, on=.(yearmon), nomatch=NULL
][,
# Step 4: count the stocks that beat the market
.(num_stk=sum(mon_ret_stk>mon_ret_mkt, na.rm=T)),
keyby=.(yearmon)
][1:3]Execution Explained:
Step 1 to 2 calculate the monthly stock return. It’s very similar to how we calculate the monthly market return previously.
Step 3: We merge the market return (which we just computed) to the stock return. The key used to join is
yearmon.Step 4: We count the stocks that beat the market.
Find out the three stocks that’re mostly correlated with the market¶
We first compute, for each stock, the correlation coefficient between the stock return and the market return. Then we select the top 10.
data[,
# Step 1: compute the market return
':='(ret_mkt=weighted.mean(retx, cap, na.rm=T)), keyby=.(date)
][,
# Step 2: calculate the correlation coefficient
.(cor_coef=cor(retx, ret_mkt), ticker=ticker[1]), keyby=.(permno)
][
# Step 3: sort and select the top 10
order(-cor_coef)][1:3]Execution Explained:
No new techniques are introduced in this problem. The only thing you need to pay attention is ticker=ticker[1] in Step 1. We only keep the first element of ticker to avoid outputting duplicated rows. Refer to this problem for details.
Find out the stock that has the largest monthly decrease in trading volume¶
My understanding of the problem: at the end of every month, we compute the percentage change in monthly trading volume for each stock, than we select the one with the largest decrease.
data[,
# Step 1: calculate the montly trading volume
# (also create the month indicator)
.(mon_prcvol=sum(prcvol)),
keyby=.(industry, yearmon=floor_date(date, 'month'))
][,
# Step 2: calculate the percentage change in trading volume
.(yearmon, mon_prcvol_change=mon_prcvol/shift(mon_prcvol)-1),
keyby=.(industry),
][,
# Step 3: remove NA
na.omit(.SD)
][
# Step 3: pick the largest decrease
order(yearmon, -mon_prcvol_change),
.SD[1],
keyby=.(yearmon)
][1:3]Execution Explained:
Step 1: Calculate monthly trading volume by aggregating the daily trading volume in the month. Note how we create the monthly indicator
yearmonin thebypart! (Yes, you can create new columns in thebypart on the fly!) Of course, you can first createyearmonand then group by it, but isn’t it cool thatdata.tablecan do two things in one shot?Step 2: Calculate monthly change. Note how we use
data.table::shiftto create a lag term ofmon_prcvol.Step 3: Pick the largest decrease. Step 3 is executed in the following order:
order(yearmon, -mon_prcvol): Sort byyearmon(ascendingly) andmon_prcvol(descendingly).keyby=.(yearmon): Then group byyearmon. Because we’ve already sorted the data, now the first row in each group has the largest decrease. Similar technique is also used in this problem..SD[1]: Select the first row in each group.
⭐️ What’s the maximum drawdown of each stock?¶
“A drawdown is a peak-to-trough decline during a specific period for an investment, trading account, or fund. A drawdown measures the historical risk of different investments, compares fund performance, or monitors personal trading performance.”
The maxinum drawdown of a stock is the largest decline of all the drawdowns in during the period. We’ll use the table.Drawdowns function from the PerformanceAnalytics package to compute the maximum drawdowns.
drawdowns <- function(ret, date, top=5) {
# This function calculates the drawdowns for a given return series
# Input:
# ret: a vector of returns
# date: a vector of dates
# top: the number of largest drawdowns to be returned
input = data.table(date, ret)[order(date)]
# a drawdown is defined whenever the cumulative return is below the previous peak
drawdowns_raw = input[, {
ret_cum=cumprod(1 + ret)
ret_cummax=cummax(c(1, ret_cum))[-1]
drawdowns=ret_cum/ret_cummax - 1
list(date, ret, ret_cum, ret_cummax, drawdowns)
}]
# find the largest drawdowns
drawdowns = drawdowns_raw[, ':='(grp = rleid(drawdowns<0))
][drawdowns<0,
.(start=date[1], trough=date[which.min(drawdowns)],
end=date[.N], depth=drawdowns[which.min(drawdowns)]),
keyby=.(grp)
][order(depth)
][1:top
][, ':='(grp=NULL)]
}
data[
# Step 1: sort by permno, date
order(permno, date)
][,
# Step 2: calculate drawdowns for each stock
{drawdowns(retx, date, top=1)},
keyby=.(permno)
][1:3]data[, .(mean(retx), sd(retx))](1/8)/(1/15.1)-1suppressWarnings({
data[
# Step 1: sort by permno, date
order(permno, date)
][,
# Step 2: calculate drawdowns for each stock
{
ret_zoo = zoo(retx, order.by=date)
PerformanceAnalytics::table.Drawdowns(ret_zoo, top=1)[, c("From", "Trough", "Depth")]
},
keyby=.(permno)
][1:3]
})Output Explained:
From: the start date of the maximum drawdown.Trough: the date of the trough of the maximum drawdown.Depth: the percentage decline, i.e., the magnitude of drawdown.
For more details about the From, Trough, Depth and perhaps other possible outputs, please refer to the documentation of the table.Drawdowns.
Execution Explained:
Step 1: Sort by
permnoanddate.Step 2: Calculate drawdowns for each stock.
We group by
permno, because the drawdown is calculated for each stock.table.Drawdownsrequires the input to be azooorxtsobject, so we create azooobject withret_zoo = zoo(retx, order.by=date). The resultingret_zooobject contains the daily stock returnretx, and its row index represents the datedate.PerformanceAnalytics::table.Drawdowns(): We call thetable.Drawdowns()function. Note that we explicitly tell R that the functdion is from thePerformanceAnalyticspackage by adding thePerformanceAnalytics::prefix. This is sometimes convenient especially when we only want to use one function withoutlibrarying the whole package.
What’s the win (success) ratio of each stock?¶
The win/loss, or success ratio, is a trader’s number of winning trades divided by the number of losing trades. When it comes to the stock like in this problem, it’s the ratio of positive-return days during the period.
data[
# Step 0: sort by permno, date
order(permno, date),
# Step 1: calculate the win ratio
.(win_ratio=sum(retx>0)/.N),
keyby=.(permno)
][1:3]Execution Explained:
Step 1: Calculate the win ratio.
sum(rex>0)gives us the number of days with positive returns. We then divide it by the total number of days (.N), which gives us the win ratio.
What’s the win ratio of the market?¶
This problem is very similar to the previous one.
data[,
# Step 1: Calculate the market daily return
.(ret_mkt=weighted.mean(retx, cap, na.rm=T)),
keyby=.(date)
][,
# Step 2: Calculat the win ratio
.(win_ratio=sum(ret_mkt>0)/.N)
]Output Explained:
Hmm... It seems there’re more gaining days than losing days.
What’s the win ratio of each industry?¶
Try it yourself before continuing to read!
data[,
# Step 1: calculate the industry return
.(ind_ret=weighted.mean(retx, cap, na.rm=T)),
keyby=.(date, industry)
][,
# Step 2: calculate the win ratio
.(win_ratio=sum(ind_ret>0)/.N),
keyby=.(industry)
][1:3]What’s the profit/loss ratio of each stock?¶
In this problem, the profit/loss ratio is defined as the average return on winning days (i.e., days with positive returns) divided by the average loss on losing days (i.e., days with negative returns):
Profit/loss ratio can also be used to evaluate the performance of a trader, see details here.
data[,
{
# Step 1: compute the variables
avg_win=mean(retx[retx>0])
avg_loss=mean(retx[retx<0])
ratio=abs(avg_win/avg_loss)
# Step 2: collect the outputs
list(avg_win=avg_win, avg_loss=avg_loss, ratio=ratio)
},
keyby=.(permno)
][1:3]Execution Explained:
Step 1: Calculate the average win/loss and the profit/loss ratio. Note that we use
retx[retx>0]to extract the positive elements inretx.Step 2: We collect the outputs into a list.
What’s the profit/loss ratio of the market?¶
Very similar to the previous one.
data[,
# Step 1: calculate the market return
.(ret_mkt=weighted.mean(retx, cap, na.rm=T)), keyby=.(date)
][,
# Step 2: calculate the win ratio
{
avg_win=mean(ret_mkt[ret_mkt>0])
avg_loss=mean(ret_mkt[ret_mkt<0])
ratio=abs(avg_win/avg_loss)
list(avg_win, avg_loss, ratio)
}
]Output Explained:
Hmm... At least in the sample period, the market is going up, as shown by the ratio being larger than one.
Is there a situation where the monthly trading volume of a stock exceeds the total daily trading volume of its industry in the same month?¶
While in real world it’s rare that we’re asked to answer such a question, but this problem is a good test of your data wrangling skills anyway.
This problem is a mouthful, let’s make sure we’re on the same page: To solve this problem, we first compute the monthly trading volume of each stock. We also calculate the minimum daily trading volume of the industry that this stock belongs to in the same month. At last, we compare the stock’s monthly trading volume with the industry’s minimum daily trading volume.
stk_mon_prcvol = data[,
# Step 1: calculate the stocks' monthly trading volume
.(stk_mon_prcvol=sum(prcvol), industry=industry[1]),
keyby=.(permno, yearmon=floor_date(date, 'month'))]
ind_mon_prcvol = data[,
# Step 2: calculate the industry's daily trading volume
.(ind_daily_prcvol=sum(prcvol)),
keyby=.(industry, date)
][,
# Step 3: find the mininum daily trading volume for each month
.(ind_min_daily_prcvol=min(ind_daily_prcvol)),
keyby=.(industry, yearmon=floor_date(date, 'month'))
]
stk_mon_prcvol[
# Step 4: join the two tables
ind_mon_prcvol, on=.(industry, yearmon), nomatch=NULL
][
# Step 4: find out the stocks meeting our criteria
stk_mon_prcvol>ind_min_daily_prcvol
][1:3]Execution Explained:
Step 1: calculate the stocks’ monthly trading volume. Note how we create a year-month indicator (
yearmon) in thebypart. The same technique is also used in, for example, this problem.Step 2: calculate the industry’s daily trading volume.
Step 3: find the minimum daily trading volume of each industry in a month.
Step 4: join the two tables: “monthly stock trading volume” and “minimum industry daily trading volume in each month”.
Step 5: select the stocks that meet our criteria.
What’s the standard deviation of returns for stocks in each industry?¶
Problem Explained:
This problems requires us to:
First, calculate the standard deviation of returns for each stocks.
Second, calculate the industry-level standard deviation, which is defined as the value-weighed average of the standard deviations of all its component stocks.
data[,
# Step 1: calculate the return sd for each stock
.(ret_sd=sd(retx), industry=industry[1], cap=mean(cap)),
keyby=.(permno)
][,
# Step 2: calculate the industry-level average sd.
.(ret_sd=weighted.mean(ret_sd, cap, na.rm=T)),
keyby=.(industry)
][1:3]Execution Explained:
Step 1: calculate the return sd for each stock. We keep
industrybecause we’ll group by it in Step 2. We also calculate the average daily market capitalcap, which will be used as the weight in Step 2.Step 2: calculate the industry-level average sd.
⭐️ For each stock, we can regress its daily returns on the market returns, which gives us one intercept term and one beta. What’s the distribution of the intercept term and the beta?¶
Problem Explained:
We’ll use many techniques introduced previously to solve this problem.
Let be the daily return for stock on day and be the market daily return. This problem first requires us to run the following regression:
Then, the problems asks about the distribution of and . There’re many ways to describe the distribution of a variable. In this problem, we focus on the following three things:
What’s the mean and variance of and ?
Plot the density of and .
alpha_beta = data[,
# Step 1: calculate the daily market return
':='(mkt_ret=weighted.mean(retx, cap, na.rm=T)),
keyby=.(date)
][,
# Step 2: get the \alpha and \beta
{
lm_out = lm(retx ~ mkt_ret)
alpha = coef(lm_out)[1]
beta = coef(lm_out)[2]
list(alpha=alpha, beta=beta)
},
keyby=.(permno)
][
# step 3: remove extreme values
alpha %between% c(quantile(alpha, 0.02), quantile(alpha, 0.98))]
alpha_beta[1:3]
alpha_beta[,
# Step 4: calculate the statistics of alpha and beta
.(alpha=mean(alpha, na.rm=T), beta=mean(beta, na.rm=T),
sd_alpha=sd(alpha, na.rm=T), sd_beta=sd(beta, na.rm=T))
]
library(ggplot2)
# Step 5: plot the distribution of alpha and beta
alpha_beta %>%
ggplot(aes(x=alpha)) +
geom_density()
alpha_beta %>%
ggplot(aes(x=beta)) +
geom_density()Output
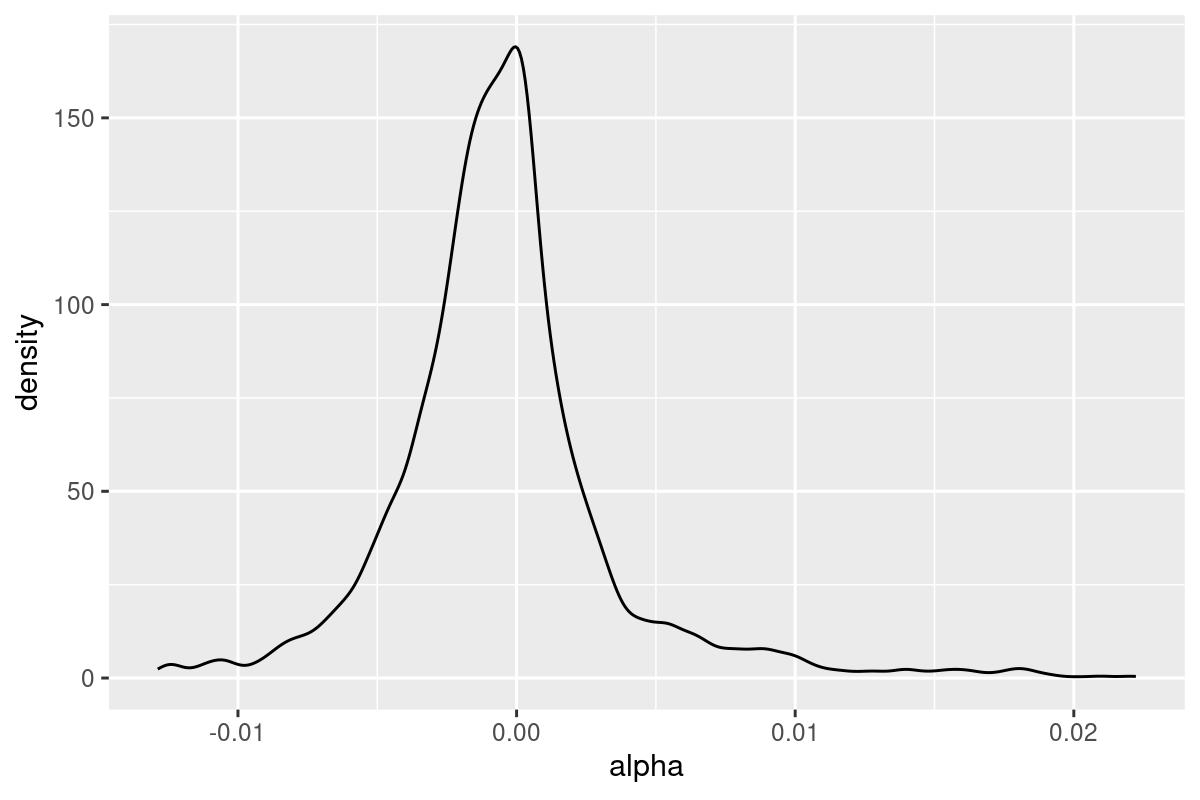
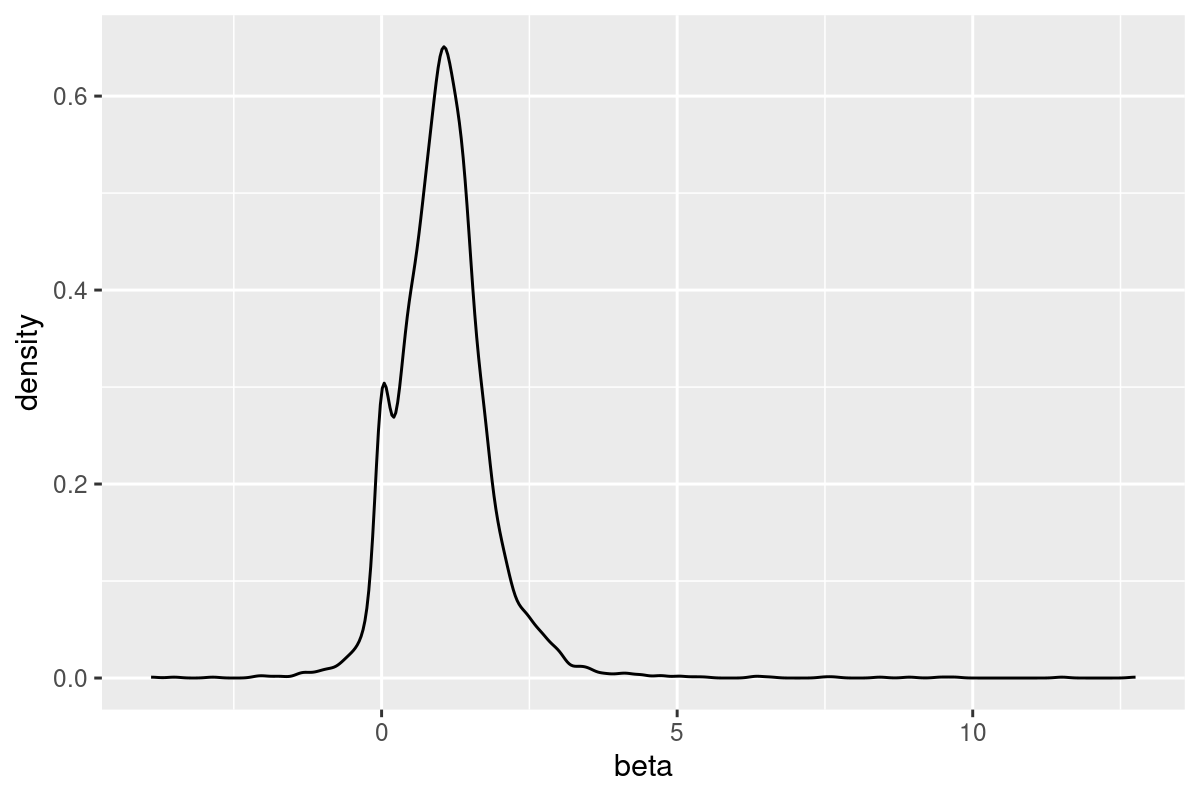
Execution Explained:
Step 1: calculate the daily market return.
Step 2: calculate the alphas and betas. The technique is introduced in this problem.
Step 3: we remove extreme values beyond the 2% and 98% percentiles. We do this to make the following visualization more clear. In real world you may not want to this.
Step 4: calculate the statistics of alpha and beta.
Step 5: plot the density of alphas and betas using
ggplot2. This is the first time we use visualization in this chapter. A quick start ofggplot2can be found here.
⭐️ Find out the stocks whose abnormal returns rank top 100 for all of the previous three days¶
Problem Explained:
This problem is a combination of problem “calculate the daily abnormal return” and problem “find out stocks that outperform the market in the past three days”. It requires us to:
First, compute the daily abnormal return for each stock.
Second, find out stocks whose abnormal return ranks top 100 in each of the past three days.
Since you’ve already learned all the necessary techniques, try it before continuing to read!
# Section 1: calculate daily abnormal return
daily_abnormal_return = data[,
':='(ret_mkt=weighted.mean(retx, cap, na.rm=T)), keyby=.(date)
][, .SD[.N>=50], keyby=.(permno)
][!is.na(retx)
][, {
lm_out = lm(retx ~ ret_mkt)
ar = resid(lm_out)
list(date, ar)
},
keyby=.(permno)]
daily_abnormal_return[1:3]Execution Explained:
Calculate the daily abnormal return for each stock. See this problem for details.
# Section 2: find out stocks whose abnormal return rank top 100 for all of the past three days
daily_abnormal_return[
# Step 1: find out the stocks whose abnormal return ranks top 100 on each day
order(date, -ar), .(permno_list=list(permno[1:100])), keyby=.(date)
][,
# Step 2: compute the number of stocks that meet the criteria
{
num_stk_3d = vector() # store the number of stocks on each day
stk_list_3d = list() # store the list of stocks on each day
for (i in 4:.N) {
# `stks` is the list of stocks that meet the criteria on each day
stks = Reduce(intersect, permno_list[(i-3):(i-1)])
stk_list_3d[[i]] = stks # don't use "[i]", you must use "[[i]]"
num_stk_3d[i] = length(stks)
}
list(date, num_stk_3d, stk_list_3d)
}
][!is.na(num_stk_3d)
][1:3]Execution Explained:
The main part of the code is very similar to this problem. I only highlight some differences:
Step 1: We first sort by
dateandar, then we group bydate. As a result, the first 100 rows in each group will have the largest abnormal return (list(permno[1:100])).Step 2: In this problem, I not only want to count the number of stocks that meet our criteria, but also want to return the
permnoof these stocks. To this end, I created two variables,num_stk_3dandstk_list_3d, to store them separately.
⭐️ Final Exam: Find out the stocks whose abnormal returns rank top 30% in the industry in all of the previous three days¶
Problem Explained:
This is the final exam, try to solve it as a test of your learning outcome!
This problem requires us to:
First, calculate the daily abnormal return of each stock.
Second, find out the stocks whose abnormal return rank top 30% in its industry in all of the previous three days.
# Section 1: calculate daily abnormal return
daily_abnormal_return = data[,
':='(ret_mkt=weighted.mean(retx, cap, na.rm=T)), keyby=.(date)
][, .SD[.N>=50], keyby=.(permno)
][!is.na(retx)
][, {
lm_out = lm(retx ~ ret_mkt)
ar = resid(lm_out)
list(date, ar, industry=industry[1])
},
keyby=.(permno)]
# Section 2: find out stocks whose abnormal return rank top 100 for all of the past three days
daily_abnormal_return[
# Step 1: find out the stocks whose abnormal return ranks top 30% in the industry on each day
order(date, industry, -ar), .(permno_list=list(permno[1:(0.3*.N)])), keyby=.(date, industry)
][,
# Step 2: (important!) unpack and repack the permno list by date
.(permno_list=list(unlist(permno_list))), keyby=.(date)
][,
# Step 3: compute the number of stocks that meet the criteria
{
num_stk_3d = vector() # store the number of stocks on each day
stk_list_3d = list() # store the list of stocks on each day
for (i in 4:.N) {
# `stks` is the list of stocks that meet the criteria on each day
stks = Reduce(intersect, permno_list[(i-3):(i-1)])
stk_list_3d[[i]] = stks # don't use "[i]", you must use "[[i]]"
num_stk_3d[i] = length(stks)
}
list(date, num_stk_3d, stk_list_3d)
}
][!is.na(num_stk_3d)
][1:3]